This work investigates the compatibility between label smoothing (LS) and knowledge distillation (KD).
Contemporary findings addressing this thesis statement take dichotomous standpoints: Muller et al. (2019); Shen et al. (2021b).
Critically, there is no effort to understand and resolve these contradictory findings,
leaving the primal question — to smooth or not to smooth a teacher network? — unanswered.
The main contributions of our work are the
discovery, analysis and validation of systematic diffusion as
the missing concept which is instrumental in understanding and resolving these contradictory findings.
This systematic diffusion essentially curtails the benefits of distilling from an LS-trained teacher, thereby rendering KD at
increased temperatures ineffective.
Our discovery is comprehensively supported by large-scale experiments, analyses and case studies including image classification,
neural machine translation and
compact student distillation tasks spanning across multiple datasets and teacher-student architectures.
Based on our analysis, we suggest practitioners to use an LS-trained
teacher with a low-temperature transfer to
render high performance students.
Discussion
While increased T is believed to be a helpful
empirical trick (Also observed in many of our experiments
when distilling from a teacher trained without LS) to produce better
soft-targets for KD, we convincingly show that
in the presence of LS-trained teacher, an increased T causes
systematic diffusion in the student. This systematic diffusion directly curtails
the distance enlargement (between semantically similar classes)
benefits of an LS-trained teacher,
thereby rendering KD ineffective at increased T . For practitioners,
as a rule of thumb, we suggest to use an LS-trained
teacher with a low-temperature transfer (i.e. T = 1) to
render high performance students. We also remark that
our finding on systematic diffusion substantially reduces
the search space for the intractable parameter T when using an LS-trained
teacher. With increasing use of KD, we hope that our findings can benefit
applications including neural architecture
search,
self-supervised learning,
compact deepfake / anomaly detection and GAN compression.
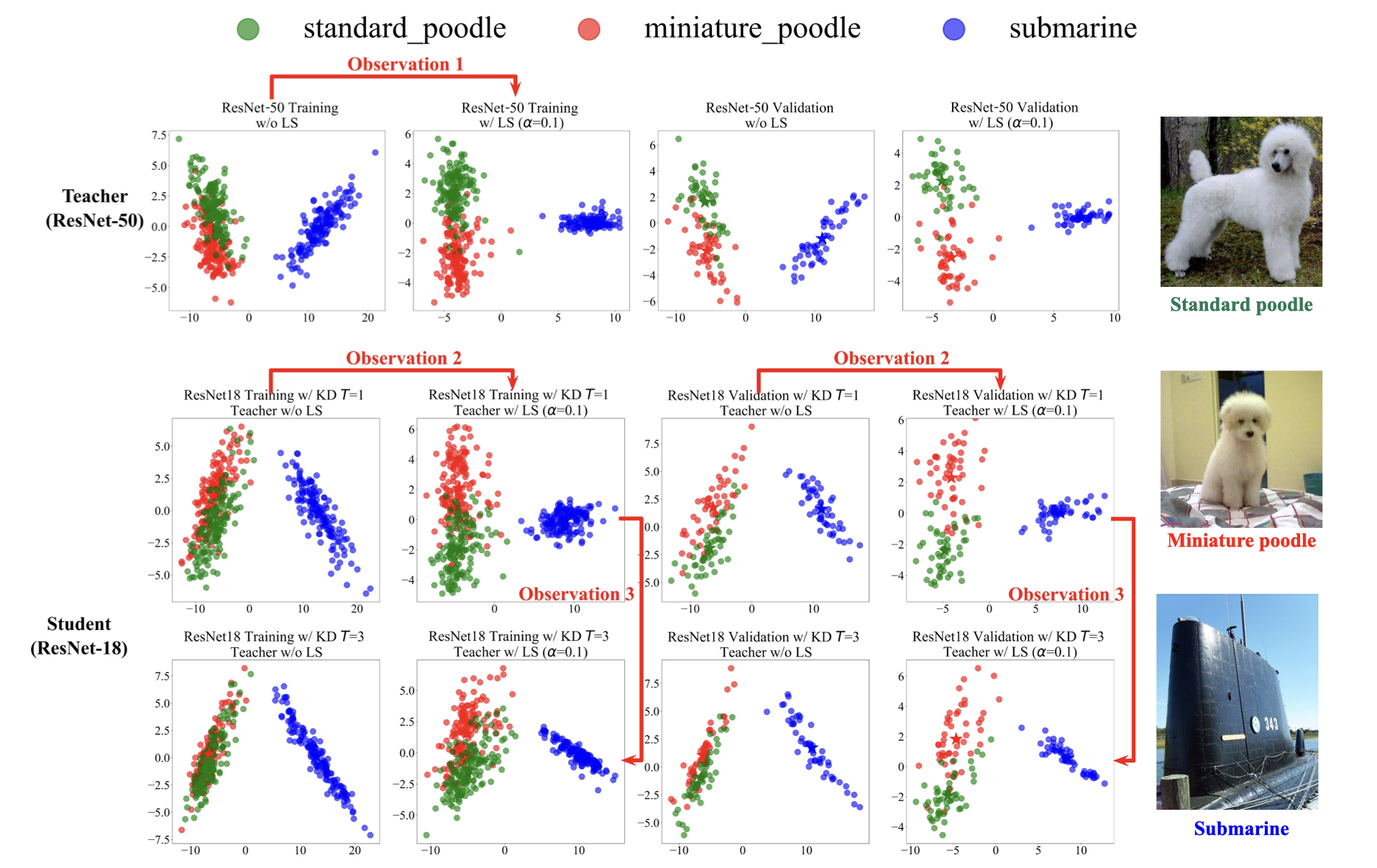
Figure 1: Visualization of the penultimate layer representations (Teacher = ResNet-50, Student = ResNet-18,
Dataset = ImageNet). We follow the same setup and procedure used in Muller et al. (2019) and Shen et al. (2021b). We
also follow their three-class analysis: two semantically similar classes (miniature poodle, standard poodle) and one seman-
tically different class (submarine). Additional visualization can be found in the Supplementary. Observation 1: The use of LS on
the teacher leads to tighter clusters and erasure of logits’ information as claimed by Muller et al. (2019). In addition, increase in central
distance between semantically similar classes (miniature poodle, standard poodle) as claimed by Shen et al. (2021b) can be
observed. Observation 2: We further visualize the student’s representations. Increase in central distance between semantically similar
classes can also be observed. This confirms the transfer of this benefit from the teacher to the student. Note that in Muller et al. (2019)
and Shen et al. (2021b), student’s representations have not been visualized. Observation 3 (Our main discovery): KD of an increased
T causes systematic diffusion of representations between semantically similar classes (miniature poodle, standard poodle).
This curtails the increment of central distance between semantically similar classes due to the use of LS-trained teacher.
Citation
@InProceedings{pmlr-v162-chandrasegaran22a,
author = {Chandrasegaran, Keshigeyan and Tran, Ngoc-Trung and Zhao, Yunqing and Cheung, Ngai-Man},
title = {Revisiting Label Smoothing and Knowledge Distillation Compatibility: What was Missing?},
booktitle = {Proceedings of the 39th International Conference on Machine Learning},
pages = {2890-2916},
editor = {Chaudhuri, Kamalika and Jegelka, Stefanie and Song, Le and Szepesvari, Csaba and Niu, Gang and Sabato, Sivan},
volume = {162},
series = {Proceedings of Machine Learning Research},
publisher = {PMLR},
month = {17-23 Jul},
year = {2022}}
Acknowledgements
This research is supported by the National Research Foundation, Singapore under its AI Singapore
Programmes (AISG Award No.: AISG2-RP-2021-021; AISG Award No.: AISG-100E2018-005). This project is
also supported by SUTD project PIE-SGP-AI-2018-01. We also gratefully acknowledge the
support of NVIDIA AI Technology Center (NVAITC) for our research